k8s运维故障 - Mon, Apr 1, 2019
k8s运维故障维护和紧急对应方案。
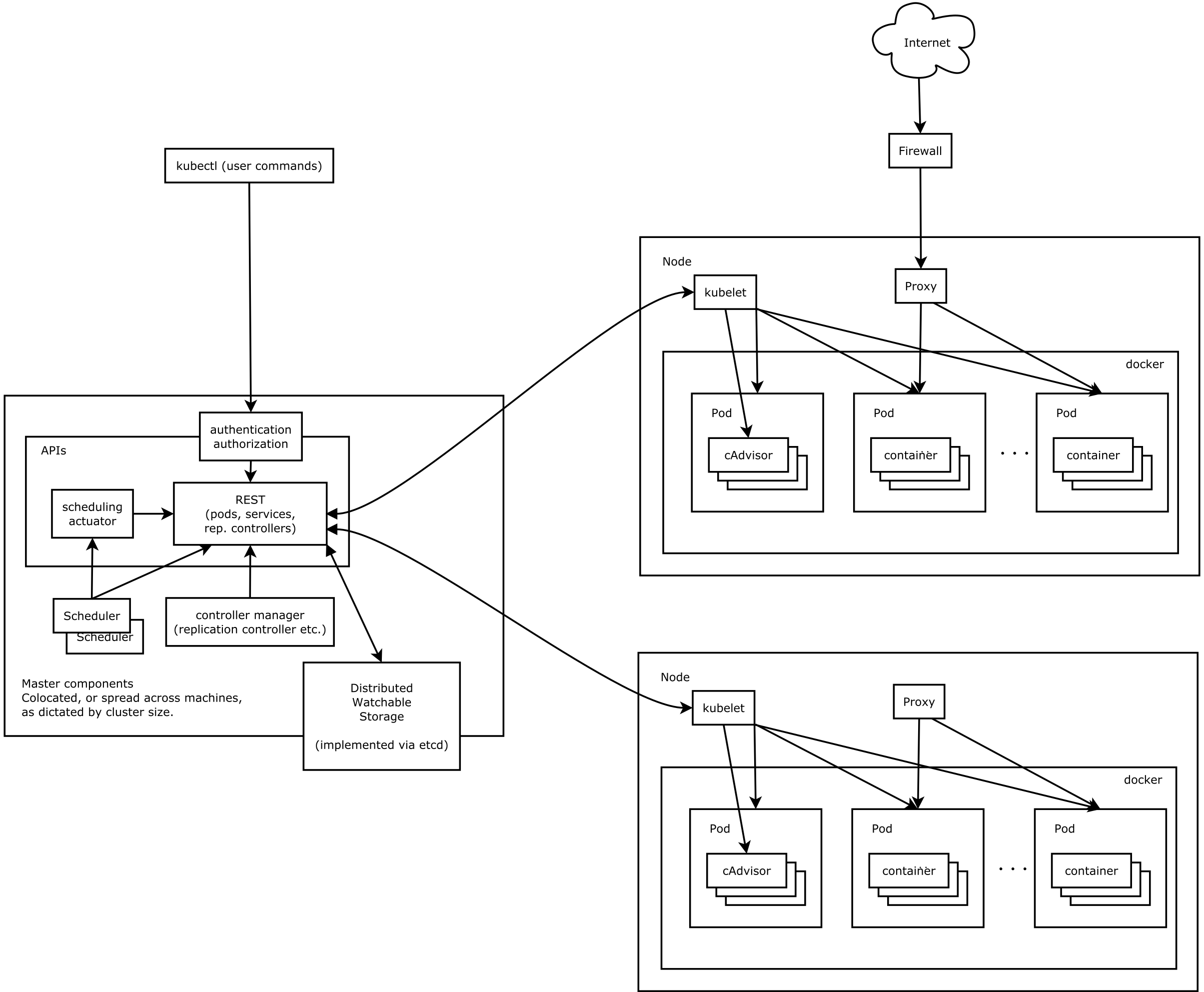
1. kubernetes(k8s)设计架构
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统。
2. kubectl常用命令
kubenetes管理工具kubectl。kubectl需要在master节点运行。
| 命令 | 作用 |
|---|---|
| kubectl annotate | 更新资源的注解。 |
| kubectl api-versions | 以“组/版本”的格式输出服务端支持的API版本。 |
| kubectl apply | 通过文件名或控制台输入,对资源进行配置。 |
| kubectl attach | 连接到一个正在运行的容器。 |
| kubectl autoscale | 对replication controller进行自动伸缩。 |
| kubectl cluster-info | 输出集群信息。 |
| kubectl config | 修改kubeconfig配置文件。 |
| kubectl create | 通过文件名或控制台输入,创建资源。 |
| kubectl delete | 通过文件名、控制台输入、资源名或者label selector删除资源。 |
| kubectl describe | 输出指定的一个/多个资源的详细信息。 |
| kubectl edit | 编辑服务端的资源。 |
| kubectl exec | 在容器内部执行命令。 |
| kubectl expose | 输入replication controller,service或者pod,并将其暴露为新的kubernetes service。 |
| kubectl get | 输出一个/多个资源。 |
| kubectl label | 更新资源的label。 |
| kubectl logs | 输出pod中一个容器的日志。 |
| kubectl patch | 通过控制台输入更新资源中的字段。 |
| kubectl port-forward | 将本地端口转发到Pod。 |
| kubectl proxy | 为Kubernetes API server启动代理服务器。 |
| kubectl replace | 通过文件名或控制台输入替换资源。 |
| kubectl rolling-update | 对指定的replication controller执行滚动升级。 |
| kubectl run | 在集群中使用指定镜像启动容器。 |
| kubectl scale | 为replication controller设置新的副本数。 |
| kubectl version | 输出服务端和客户端的版本信息。 |
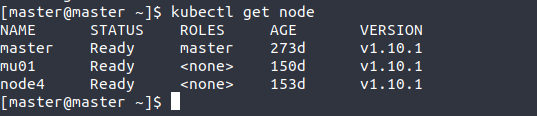
2.1 获取节点状态
kubectl get node
- NAME: 节点名
- STATUS: 节点状态(Ready为正常,NotReady为不正常)
- ROLES: 节点的角色
- AGE: 节点运行时间
- VERSION: k8s版本
2.2 设定节点进入维护状态
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
2.3 删除节点
kubectl delete node <node name>
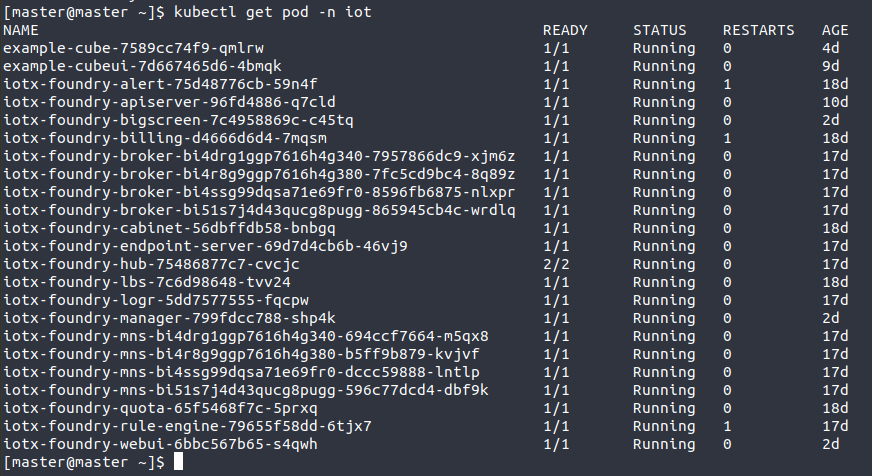
2.4 获取服务状态
kubectl get pod -n iot
- POD: k8s种最小资源单位
- -n: namespace的缩写(获取指定名空间下的资源状态)
- NAME: POD名
- READY: 资源副本数
- STATUS: 状态
- RESTARTS: 重启次数
- AGE: 运行时间
2.5 重启服务
由RC或RS进行管理的POD删除之后会自动创建,我们可以利用这点强制重启POD。(单一POD不适用)
kubectl delete pod <pod name> -n iot
2.6 服务日志
查看某个服务的日志
kubectl logs <pod name> -n iot -f
- -n: namespace的缩写(获取指定名空间下的资源)
- -f: 日志持续输出
3. kubeadm常用命令
| 命令 | 作用 |
|---|---|
| kubeadm init | 初期化k8s的master |
| kubeadm join | 将Node节点加入集群 |
| kubeadm reset | 初期化节点(kubeadm init 或 kubeadm join) |
| kubeadm token | 管理token |
| kubeadm upgrade | 升级k8s集群 |
| kubeadm version | kubeadm版本 |
4. helm常用命令
| 命令 | 作用 |
|---|---|
| helm install | 安装chart |
| helm upgradge | 更新chart |
| helm ls | 列出所有chart |
| helm delete | 删除所有chart |
4.1 安装chart
将chart安装到指定的名空间下。 多次更新同一资源会保留最新的资源
helm install <chart> --namespace=iot
4.2 更新
更新chart
helm upgrade <chart> --namespace=iot
4.3 列出所有chart
helm ls
- NAME: chart名
- REVISION: 更新的版本数
- UPDATED: 上次更新时间
- STATUS: chart状态
- chart: app名
- APP VERSION: app版本
- NAMESPACE: k8s名空间

4.4 删除chart
删除chart但是更新记录仍然会存在
helm delete <chart name>
完全删除chart
helm delete <chart name> --purge
5. 可视化管理工具
kubernetes(k8s)提供了集群可视化管理工具dashboard。
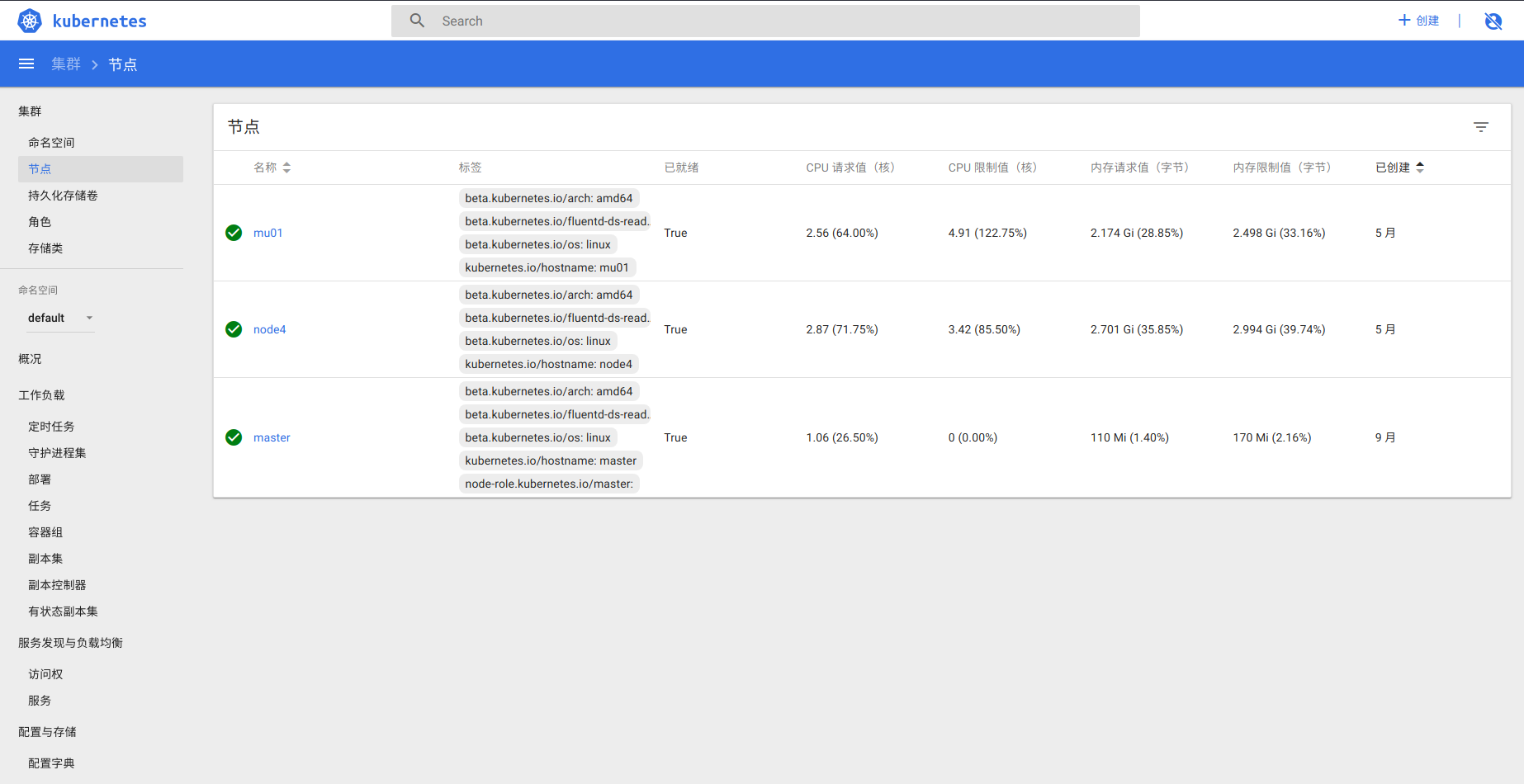
5.1 集群状态
侧边栏-集群-节点
5.2 服务状态
侧边栏-命名空间
侧边栏-工作负载-容器组
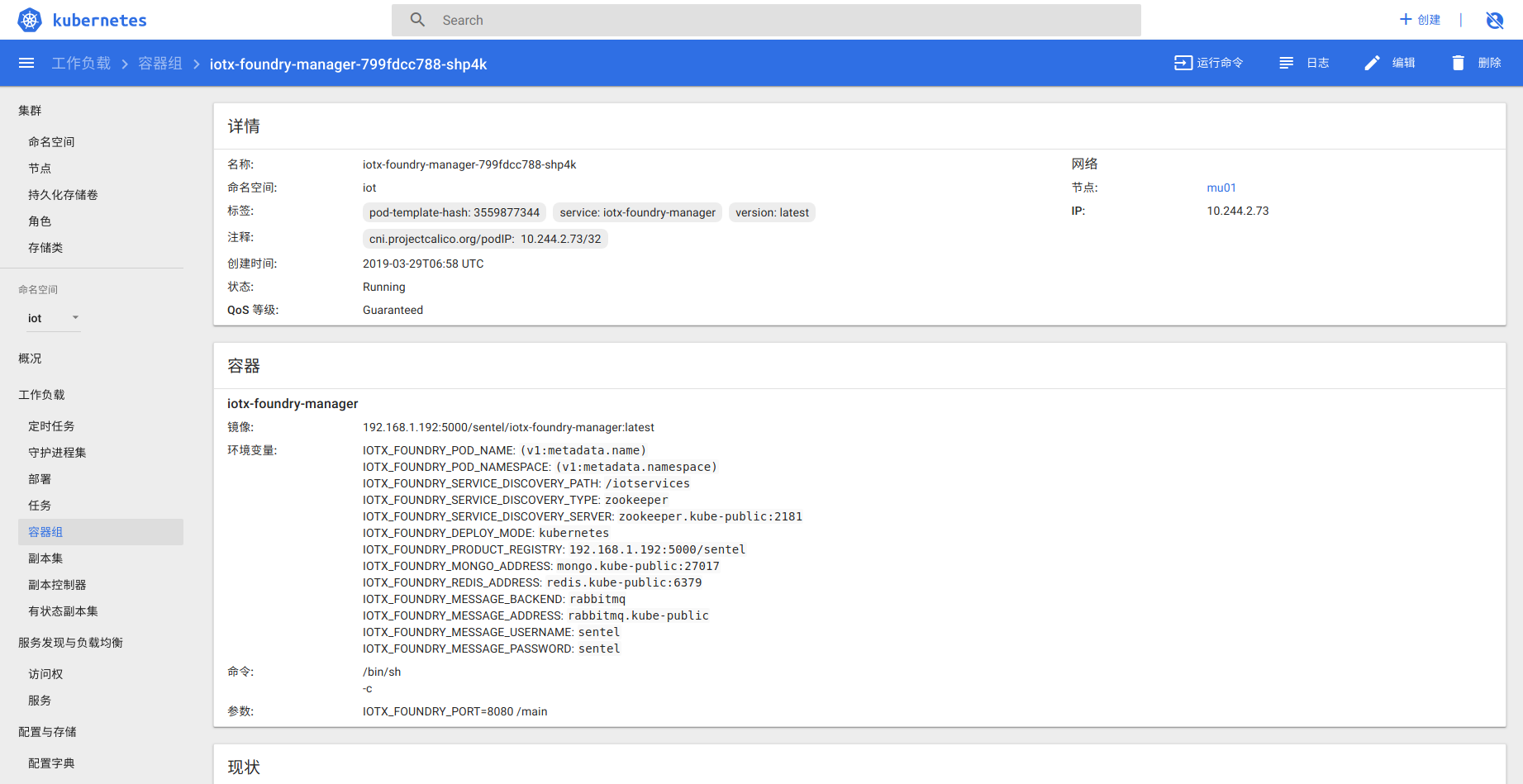
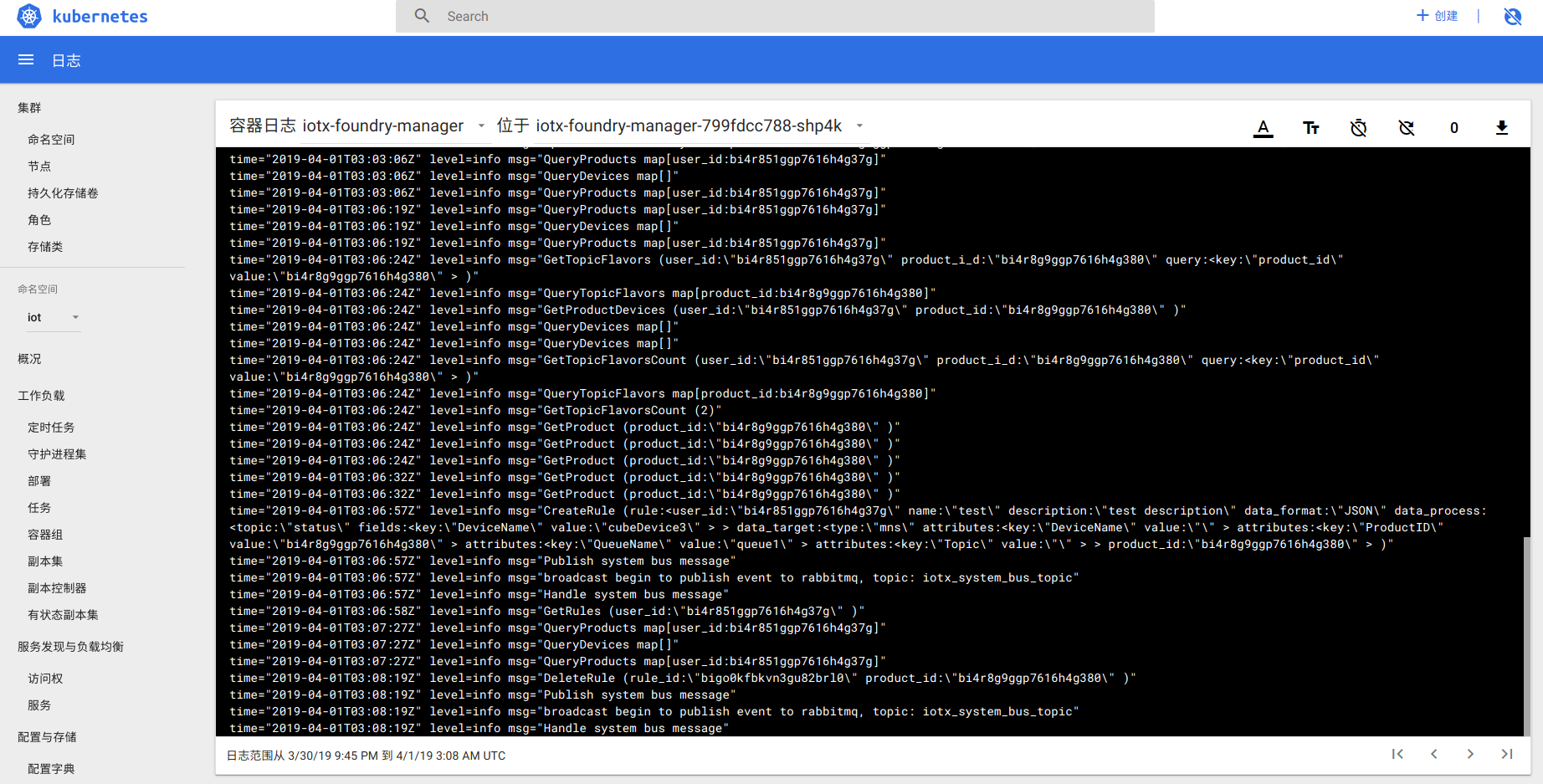
5.3 服务日志
侧边栏-工作负载-容器组-<服务>-日志
6. 服务器故障
6.1 全服务器断电
全服务器断电,只需要把服务器重新启动,服务会自动部署和重启。
启动顺序: 数据服务器->master节点->node节点
6.2 Node节点服务器故障
故障服务器重启之后,master会自动控制Node节点进行服务启动和部署。
6.3 master节点服务器故障
故障服务器重启之后,其他master会自动控制master节点进行服务启动和部署。
6.4 Node节点服务器追加
使用kubeadmin初期话Node节点。kubeadm创建集群
使用
kubeadmin join将节点加入集群Node加入集群之后,master会自动对服务进行管理。
6.5 Master/Node节点服务器删除
6.5.1 设定节点为维护状态
如果节点与集群断开连接,则不需要执行
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
6.5.2 从集群内删除节点
kubectl delete node <node name>
6.6 服务故障无法自动重启
6.6.1 截取故障服务的日志
由于硬件原因或者第三方服务愿意,导致服务重启之后立刻失败。 这种情况需要针对日志进行分析。
kubectl截取日志
kubectl logs <pod name> <pod name>.log
dashboard的日志页面,点击下载按钮下载日志
6.6.2 重启服务
由RC或RS进行管理的POD删除之后会自动创建,我们可以利用这点强制重启POD。(单一POD不适用)
kubectl delete pod <pod name> -n iot
dashboard: 通过删除容器重启服务
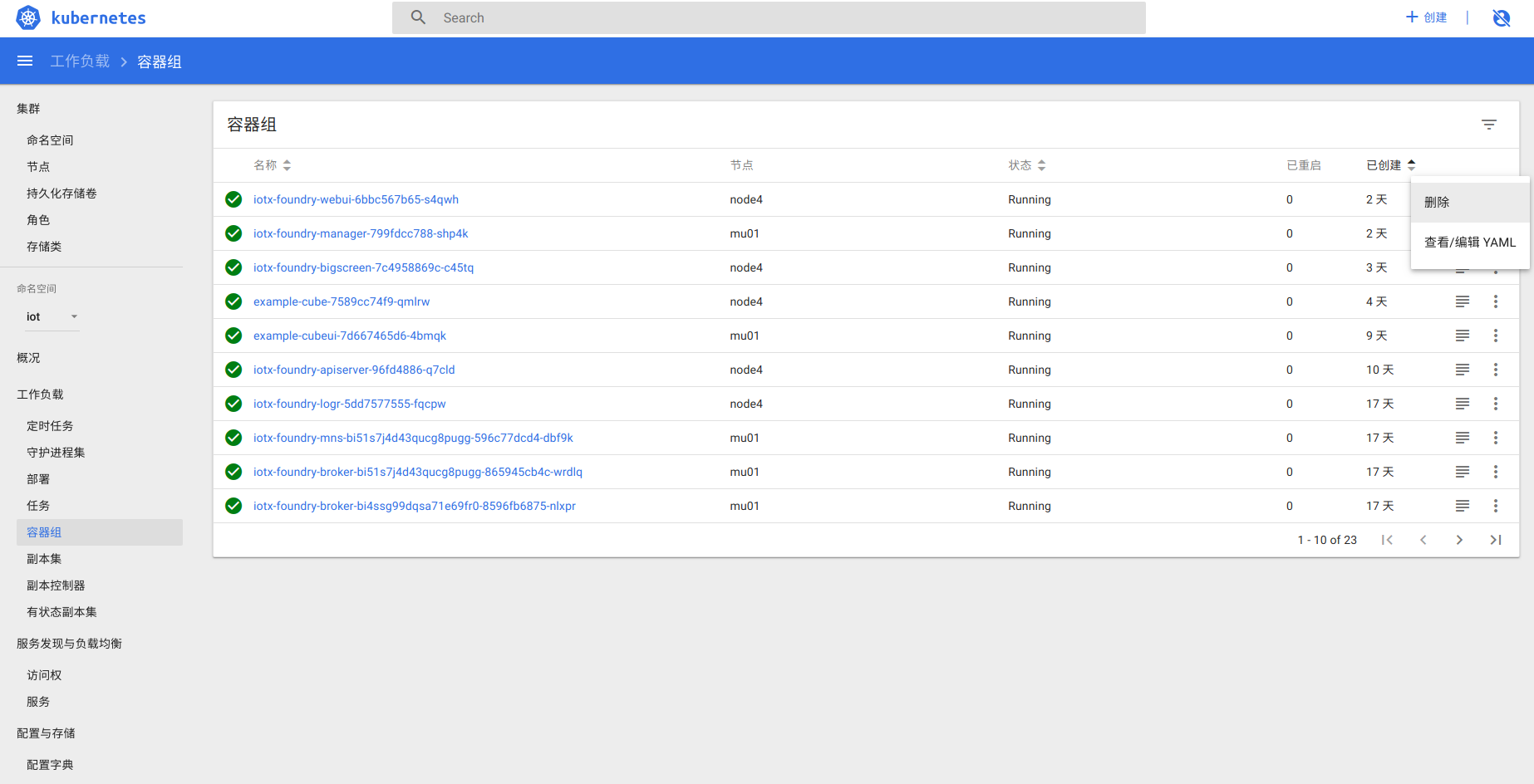
6.7 更新服务
6.7.1 获取更新之后的服务镜像
从远程服务器获取镜像
docker pull <镜像名>
从镜像文件加载
docker load <镜像名>
6.8.2 重命名镜像
docker tag <镜像名> <k8s集群镜像名>
6.8.3 上传镜像到本地服务器
docker push <k8s集群镜像名>
6.8.4 重启服务
由RC或RS进行管理的POD删除之后会自动创建,我们可以利用这点强制重启POD。(单一POD不适用)
kubectl delete pod <pod name> -n iot
dashboard: 通过删除容器重启服务
6.9 数据库修改
数据库文件被保存到了数据服务器,并且进行了备份操作。如果需要修改数据库,不能修改数据库文件,需要通过mongodb进行间接修改。(尽量不要这么做!)
获取局域网能够访问到的数据库地址:
kubectl get service mongo-service -n kube-public

通过dashboard查看
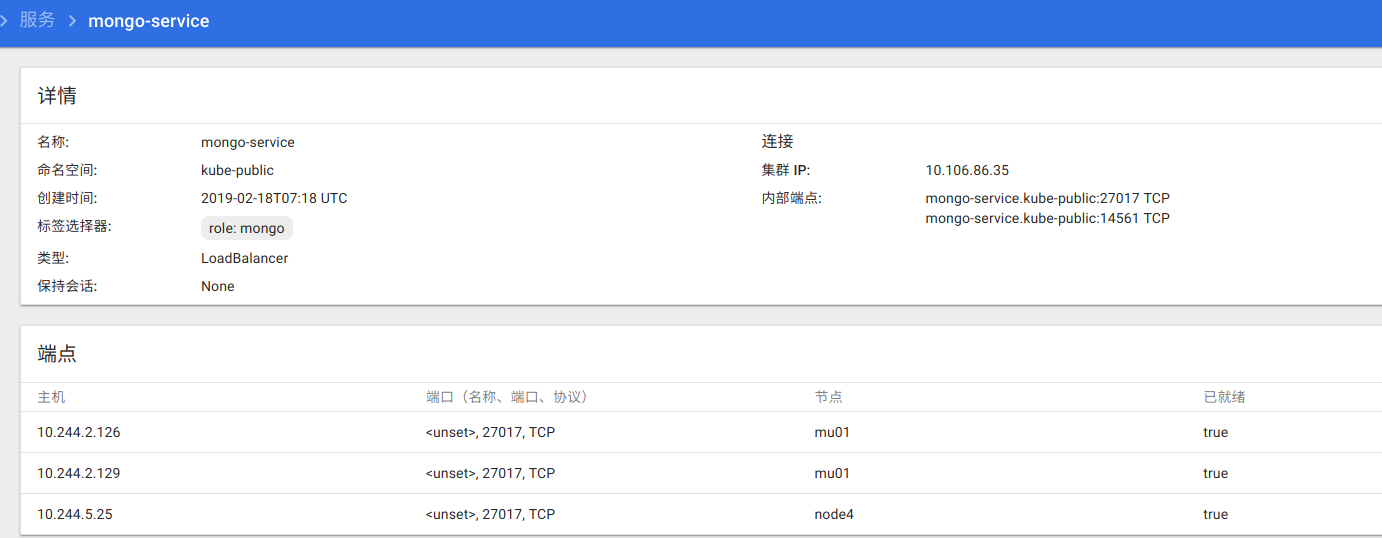
mongodb局域网地址:<master ip>:14561
6.10 更新服务属性
虽然可以通过直接修改k8s资源的方式修改服务属性,但是由于k8s的资源是通过helm进行维护,在下次helm upgrade时,直接修改的属性将会丢失,所以需要通过helm进行属性的修改。
helm upgrade <chart name> --namespace=iot